

Redundant and RAID 6
The drives are connected by dual SAS controllers with RAID 6 data protection. With RAID 5, you can recover your data by rebuilding the RAID array after one drive fails. But if you lose a second drive while you are rebuilding the array – or if you accidentally remove the wrong drive before you start the rebuild – you could lose data. RAID 6 adds a second parity stripe across each element of the array, giving you a second level of protection. One drive in the RAID set may fail but it’s far less likely that two drives will; and when a drive fails, the data is still protected even while you’re rebuilding the array.
This adds up to a fully dual redundant switched fabric between the blades and the storage, although Callahan won’t yet go into details about the technology. “There are dual paths to each drive, dual controllers fronting each drive, dual paths from the controller to the blades, dual switches in the blade chassis and dual connections from the switches to the blade,” Callahan said.
The SAS switch in the ExDS9100 means you don’t need external switches, interconnects or extra cabling within the data center. Avoiding fibre channel helps keep the overall cost down, and HP says it uses its buying power to keep the disk prices low. Current enterprise storage costs are around $15 per gigabyte, while HP promises the ExDS9100 will be “dramatically cheaper” than the other storage it sells, costing less than $2/GB. That still adds up to $500,000 for the standard 246TB or $1.64 million for 820TB.
Callahan predicts costs will continue to drop to a price of 11 cents per GB by 2011 for spinning disks and under a dollar for the same amount of solid state drive media, while adding that HP is working on “lots of interesting I things can’t talk about now.»
But when you’re pricing a petabyte system, it’s not just the purchase price that matters, it’s how much it will cost to keep it running. Multiple petabytes of storage mean there will be many thousands of spinning disks, some of which will fail. Distributed software and RAID protect data in case of disk failure, but you’ll still have to replace failed parts. Designing a system that makes it quicker and simpler to replace failed disks will thus save costs because you don’t need as much staff to run the system.
When drives or the fans in the disk enclosures fail, the PolyServe software tells you which one has failed and where – and gives you the part number for ordering a replacement. Add a new blade or replace one that’s failed and you don’t need to install software manually. When the system detects the new blade, it configures it automatically. That involves imaging it with the Linux OS, the PolyServe storage software and any apps you have chosen to run on the ExDS; booting the new blade; and adding it to the cluster. This is all done automatically. Automatically scaling the system down when you don’t need as much performance as you do during heavy server-load periods or marking data that doesn’t need to be accessed as often, also keeps costs down.
HP packs drives together more densely than most storage arrays, manages them with PolyServe to cut the costs of running the array and uses its buying power to push down the cost of the individual drives as well. Power usage and cooling needs are well within the range of what modern data centers can deliver, says Callahan but he admits that’s high, joking that “it also makes a great space heater.”
One option for reducing power and cooling costs is MAID, which comprises massive arrays of inactive disks that power down most of the drives most of the time. The first generation of ExDS does use MAID, but Callahan says HP is looking at the options. “Obviously it would be a nice idea, if you have a lot of drives in an environment, to not to have to spin all of them all the time,” Callahan said. “In the first release, though, we do spin all of them all the time.”


Diagrama de una configuración RAID 6. Cada número representa un bloque de datos; cada columna, un disco; p y q, códigos Reed-Solomon.
Un RAID 6 amplía el nivel RAID 5 añadiendo otro bloque de paridad, por lo que divide los datos a nivel de bloques y distribuye los dos bloques de paridad entre todos los miembros del conjunto. El RAID 6 no era uno de los niveles RAID originales.
El RAID 6 puede ser considerado un caso especial de código Reed-Solomon.1 El RAID 6, siendo un caso degenerado, exige sólo sumas en el campo de Galois. Dado que se está operando sobre bits, lo que se usa es un campo binario de Galois (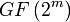 ). En las representaciones cíclicas de los campos binarios de Galois, la suma se calcula con un simple XOR.
). En las representaciones cíclicas de los campos binarios de Galois, la suma se calcula con un simple XOR.
Tras comprender el RAID 6 como caso especial de un código Reed-Solomon, se puede ver que es posible ampliar este enfoque para generar redundancia simplemente produciendo otro código, típicamente un polinomio en 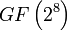 (m = 8 significa que estamos operando sobre bytes). Al añadir códigos adicionales es posible alcanzar cualquier número de discos redundantes, y recuperarse de un fallo de ese mismo número de discos en cualesquiera puntos del conjunto, pero en el nivel RAID 6 se usan dos únicos códigos.
(m = 8 significa que estamos operando sobre bytes). Al añadir códigos adicionales es posible alcanzar cualquier número de discos redundantes, y recuperarse de un fallo de ese mismo número de discos en cualesquiera puntos del conjunto, pero en el nivel RAID 6 se usan dos únicos códigos.
Al igual que en el RAID 5, en el RAID 6 la paridad se distribuye en divisiones (stripes), con los bloques de paridad en un lugar diferente en cada división.
El RAID 6 es ineficiente cuando se usa un pequeño número de discos pero a medida que el conjunto crece y se dispone de más discos la pérdida en capacidad de almacenamiento se hace menos importante, creciendo al mismo tiempo la probabilidad de que dos discos fallen simultáneamente. El RAID 6 proporciona protección contra fallos dobles de discos y contra fallos cuando se está reconstruyendo un disco. En caso de que sólo tengamos un conjunto puede ser más adecuado que usar un RAID 5 con un disco de reserva (hot spare).
La capacidad de datos de un conjunto RAID 6 es n-2, siendo n el número total de discos del conjunto.
Un RAID 6 no penaliza el rendimiento de las operaciones de lectura, pero sí el de las de escritura debido al proceso que exigen los cálculos adicionales de paridad. Esta penalización puede minimizarse agrupando las escrituras en el menos número posible de divisiones (stripes), lo que puede lograrse mediante el uso de un sistema de ficheros WAFL.