

Sistemas RAID, Redundant Array of Inexpensive Disks
1. Introduccion
Gracias a la uní versificación de la informática, más personas están en contacto con el mundo de los ordenadores, ya sea para uso personal o profesional. Todo ha servido para una evoluciónmás rápida de los diferentes componentes de los ordenadores. Desde hace 20 años la capacidad de proceso de los procesadores ha aumentado un 40 % cada año. En el mismo periodo detiempo, los discos han doblado su capacidad cada año, mientras que su costo se ha reducido a la mitad. Desgraciadamente, el aumento del rendimiento de los discos duros ha sido menos importante en comparación con el rendimiento del sistema, ya que tan solo ha mejorado un 50 % durante la última década.
Por lo que teníamos y tenemos un problema con los discos duros, que son menos eficaces que el redimiendo general del sistema, provocando una descompensación entre el tratamiento de lainformación del sistema (muy rápido) y la lectura – grabación de datos en el disco duro(muy lenta). Para ello se invento un sistema para guardar información en varios discos duros a la vez por lo que acceso se hacia más rápido ya que la carga se distribuía entre los diferentes discos duros, a esto se le llamo cadenas redundantes de discos de bajo costo (RAID). Pero a la hora de saber como podemos optimizar nuestro
RAID nos encontrábamos con algunos problemas, como puede ser encontrar la perfecta relación calidadprecio
En este Trabajo se intentará explicar que es RAID que tipos existen y que modelo es el que mejor se ajusta a las necesidades de cada usuario.

2. ¿Que es RAID?
RAID es una forma de almacenar los mismos datos en distintos lugares (por tanto de modo redundante) en múltiples discos duros. Al colocar los datos en discos múltiples, las operaciones I/O (input/output, de entrada y salida) pueden superponerse de un modo equilibrado, mejorando el rendimiento del sistema. Dado que los discos múltiples incrementan el tiempo medio entre errores (mean time between failure, MTBF), el almacenamiento redundante de datos incrementa latolerancia a fallos.
Un RAID, para el sistema operativo, aparenta ser un sólo disco duro lógico. El RAID emplea la técnica conocida como «striping» (bandeado o creación de bandas), que incluye la partición del espacio de almacenamiento de cada disco en unidades que van de un sector (512 bytes) hasta varios megabytes. Las bandas de todos los discos están interpaginadas (interleaved) y se accede a ellas en orden.
En un sistema de un solo usuario donde se almacenan grandes registros (como imágenes médicas o de otro tipo), las bandas generalmente se establecen para ser muy pequeñas (quizá de 512 bytes) de modo que un solo registro esté ubicado en todos los discos y se pueda acceder a él rápidamente leyendo todos los discos a la vez.
En un sistema multiusuario, un mejor rendimiento demanda que se establezca una banda lo suficientemente ancha para contener el registro de tamaño típico o el de
mayor tamaño. Esto permite acciones I/O superpuestas en los distintos discos.
Básicamente el RAID es un sistema el cual permite almacenar información en una cantidad de discos (n), de tal forma que agilice el proceso maquina-disco.
El sistema RAID evitará en lo más posible la pérdida de data de la siguiente manera:
Los discos optimizados para RAID poseen circuitos integrados que detecta si el disco está fallando, de ser así este circuito se encargará por encima del tiempo real de sacar la información y almacenarla en los otros discos, o si es el caso en el «hot spare».
Un hot spare es un disco que permanece siempre en el sistema esperando a que otro se estropee y él entre directamente en funcionamiento.
Una de las ventajas del sistema RAID es la posibilidad, con los discos hot swap, de conectarlos y desconectarlos en «caliente», es decir, que si un disco falla no hará falta el apagar el sistema para remplazarlo.
Otras de las ventajas de RAID:
- Reconstrucción y Regeneración Cuando un disco falla la información redundante en los discos y los datos en los discos buenos son usados para regenerar la información de disco averiado.
Striping Es el acto de unir dos o más discos físicos en un solo disco lógico con el fin de dividir los datos entre los diferente discos para ofrecer una significativa mejora en el rendimiento del conjunto de los discos.
![]()
Los datos son divididos a través de los discos. La lectura y escritura es compartida
La búsqueda de datos clásica fuerza a la lectura y escritura a no recordar su posición

resultando más movimientos de cabezas y peor eficiencia

La lectura de datos es etiquetada y reordenada. Los movimientos de las cabezas de lectura – escritura se realizan mas eficientemente cuando se buscan datos.
Historia del RAID
El término RAID hizo su debut oficial en 1989 en forma de un paper publicado por David Paterson, Garth Gibson y Randy Katz, todos ellos de la Universidad de California. El paper se titulaba «A case for Redundant Array of Inexpensive Disks».
En dicho trabajo el equipo definió cinco niveles para arreglos de discos cuyas funciones eran ofrecer mejoras en el rendimiento, confiabilidad, tasa de transferencia y tasas de lectura/escritura. Cada nivel tiene sus propias ventajas y desventajas, las cuales iremos revisando en el transcurso de la lectura.
Desde entonces, múltiples fabricantes han introducido y/o desarrollado variaciones a estos cinco niveles originales y las han bautizado en acuerdo a las genialidades de sus respectivos Departamentos de Marketing. Para propósitos de esta lectura usaremos las definiciones especificadas por el RAID Advisory Board, que es una institución conformada por un grupo de 40 empresas entre fabricantes y desarrolladores interesados en el tema de RAID y en su estandarización.
En el trabajo original el término RAID se refería a Redundant Array of Inexpensive Disks como una contraposición directa a los SLED (Single Large Expensive Disks). Sin embargo, las increíbles bajas en los precios de los discos duros han ocasionado que los SLED prácticamente desaparezcan, por lo tanto, el significado de la sigla ha cambiado y en la actualidad se la traduce como Redundant Array of Independent Disks.
4. Ventajas de los discos RAID
El rendimiento general del sistema aumenta ya que pueden funcionar de forma paralela con los diferentes discos del conjunto.
Dependiendo del nivel de RAID que escojamos, si uno de los discos del conjunto falla, la unidad continúa funcionando, sin pérdida de tiempo ni de datos. La reconstrucción de los datos del disco que ha fallado se hace de forma automática sin intervención humana. En el caso de algunos sistemas operativos la regeneración de datos se hace desde software por ejemplo en el Windows NT, aunque en estos sistemas se pueden usar controladoras RAID q
ue sí regenerarían los datos automáticamente.
La capacidad global del disco aumentará, ya que se suman las capacidades de los diferentes discos que componen el conjunto.
¿Porqué usar RAID?
Las operaciones de I/O a disco son relativamente lentas, primordialmente debido a su carácter mecánico. Una lectura o una escritura involucra, normalmente, dos operaciones. La primera es el posicionamiento de la cabeza lecto/grabadora y la segunda es la transferencia desde o hacia el propio disco.
El posicionamiento de la cabeza está limitado por dos factores: el tiempo de búsqueda (seek time) y el retardo por el giro del disco hasta la posición de inicio de los datos (latencia rotacional). La transferencia de datos, por su parte, ocurre de a un bit por vez y se ve limitada por la velocidadde rotación y por la densidad de grabación del medio
Una forma de mejorar el rendimiento de la transferencia es el uso de varios discos en paralelo; esto se basa en el hecho de que si un disco solitario es capaz de entregar una tasa de transferencia dada, entonces dos discos serían capaces, teóricamente, de ofrecer el doble de la tasa anterior; lo mismo sucedería con cualquier operación.
La adición de varios discos debería extender el fenómeno hasta un punto a partir del cual algún otro componente empezará a ser el factor limitante.
Muchos administradores o encargados de sistemas intentan llevar a cabo esta solución en forma básicamente manual, distribuyendo la información entre varios discos de tal forma de intentar asegurar una carga de trabajo similar para cada uno de ellos. Este proceso de «sintonía» podría dar buenos resultados de no ser por dos factores principales:
No consigue mejorar las velocidades de transferencia de archivos individuales, sólo mejora la cantidad de archivos accesados en forma concurrente.
Es obvio que el balance no es posible de mantener en el tiempo debido a la naturaleza eminentemente dinámica de la información.
Una forma bastante más efectiva de conseguir el objetivo es el uso de un arreglo de discos, el cual según la definición del RAID Consultory Board es «una colección de discos que integran uno o más subsistemas combinados con un software de control el cual se encarga de controlar la operación del mismo y de presentarlo al Sistema Operativo como un sólo gran dispositivo de almacenamiento». Dicha pieza de software puede ser integrada directamente al Sistema Operativo o residir en el propio arreglo; así como el arreglo puede ser interno o externo.
Novell Netware incluye, desde hace algún tiempo, soporte para arreglos de discos. El espejado y la duplicación de discos son ejemplos de arreglos basados en software. Más recientemente fabricantes independientes han ofrecido al mercado arreglos de discos basados en software que pueden correr en formato NLM (Netware Loadable Module) sobre un Servidor Netware.
Las soluciones de arreglos basadas en hardware son principalmente implementadas mediante el uso de controladoras SCSI (Small Computer System Interface) especializadas, las cuales a menudo están dotadas de procesadores propios para liberar a la CPU del sistema de la tarea de control y de cachés para mejorar aún más el desempeño.
Para Netware cualquiera de las dos soluciones, software o hardware, será visualizada como un único y gran disco virtual.
Así pues un arreglo de discos ofrecerá un mejor desempeño debido a que dividirá en forma automática los requerimientos de lectura/escritura entre los discos que lo conforman. Por ejemplo, si una operación de lectura/escritura involucra a cuatro bloques de 4 Kb cada uno, entonces un arreglo de 4 discos podría, teóricamente, entregar cuatro veces la tasa de operación de un disco único, esto debido a que el disco único sólo podría atender a un bloque en forma simultánea, mientras que en el arreglo cada disco podría manejar un sólo bloque cada uno y como operan al mismo tiempo
En la práctica, sin embargo, dichos niveles no se obtienen debido, principalmente, a la carga de trabajo inherente al control del propio arreglo. Además el uso de varios discos se emplea para construir cierto nivel de redundancia de los datos y es este nivel de redundancia y la forma de implementarlo lo que crea los niveles de RAID.
Arreglos paralelos vs. independientes
Arreglos paralelos: éstos son aquellos en que cada disco participa en todas las operaciones de entrada/salida. Este tipo de arreglo ofrece tasas altísimas de transferencia debido a que las operaciones son distribuidas a través de todos los discos del arreglo y ocurren en forma prácticamente simultánea. La tasa de transferencia será muy cercana, 95%, a la suma de las tasas de los discos miembros, mientras que los índices de operaciones de entrada/salida serán similares a las alcanzadas por un disco individual. En español: un arreglo paralelo accesará sólo un archivo a la vez pero lo hará a muy alta velocidad. Algunas implementaciones requieren de actividades adicionales como la sincronización de discos.
Los RAID de niveles 2 y 3 se implementan con arreglos paralelos.
Arreglos independientes: son denominados así aquellos arreglos en los cuales cada disco integrante opera en forma independiente, aún en el caso de que le sea solicitado atender varios requerimientos en forma concurrente. Este modelo ofrece operaciones de entrada/salida sumamente rápidas debido a que cada disco está en posición de atender un requerimiento por separado. De esta forma las operaciones de entrada/salida serán atendidas a una velocidad cercana, 95%, a la suma de las capacidades de los discos presentes, mientras que la tasa de transferencia será similar a la de un disco individual debido a que cada archivo está almacenado en sólo un disco. Los niveles 4 y 5 de RAID se implementan con arreglos independientes, mientras que los niveles 0 y 1 pueden ser implementados por cualquiera de las categorías, sin perjuicio de suelan ser implementados en forma de arreglos independientes.
Stripping y mirroring
RAID a niveles 0, 1 y 0 & 1 puede ser implementado, tanto en forma de arreglos independientes o paralelos. Netware lo implementa como arreglos independientes a nivel del propio Sistema Operativo y, por lo tanto, no precisa de hardware o software adicional.
Niveles de RAID
La elección de los diferentes niveles de RAID va a depender de las necesidades del usuario en lo que respecta a factores como seguridad, velocidad, capacidad, coste, etc. Cada nivel de RAID ofrece una combinación específica de tolerancia a fallos (redundancia), rendimiento y coste, diseñadas para satisfacer las diferentes necesidades de almacenamiento. La mayoría de los niveles RAID pueden satisfacer de manera efectiva sólo uno o dos de estos criterios. No hay un nivel de RAID mejor que otro; cada uno es apropiado para determinadas aplicaciones y entornos informáticos. De hecho, resulta frecuente el uso de varios niveles RAID para distintas aplicaciones del mismo servidor. Oficialmente existen siete niveles diferentes de RAID (0-6), definidos y aprobados por el el RAID Advisory Board (RAB). Luego existen las posibles combinaciones de estos niveles (10, 50, …). Los niveles RAID 0, 1, 0+1 y 5 son los más populares.
RAID 0: Disk Striping «La más alta transferencia, pero sin tolerancia a fallos».
También conocido como «separación ó fraccionamiento/ Striping«. Los datos se desglosan en pequeños segmentos y se distribuyen entre varias unidades. Este nivel de «array» o matrizno ofrece tolerancia al fallo. Al no existir redundancia, RAID 0 no ofrece ninguna protección de los datos. El fallo de cualquier disco de la matriz tendría como resultado la pérdida de los datos y sería necesario restaurarlos desde una copia de seguridad. Por lo tanto, RAID 0 no se ajusta realmente al acrónimo RAID. Consiste en una serie de unidades de disco conectadas en paralelo que permiten una transferencia simultánea de datos a todos ellos, con lo que se obtiene una gran velocidad en las operaciones de lectura y escritura. La velocidad de transferencia de datos aumenta en relación al número de discos que forman el conjunto. Esto representa una gran ventaja en operaciones secuenciales con ficheros de gran tamaño. Por lo tanto, este array es aconsejable en aplicaciones de tratamiento de imágenes, audio, video o CAD/CAM, es decir, es una buena solución para cualquier aplicación que necesite un almacenamiento a gran velocidad pero que no requiera tolerancia a fallos. Se necesita un mínimo de dos unidades de disco para implementar una solución RAID 0.
<
img src="http://2.bp.blogspot.com/_4xfX48NAgYs/SYV2hfsxh-I/AAAAAAAABnQ/f1wu1Zv9BU8/s200/raid0.jpg" border="0" alt="" id="BLOGGER_PHOTO_ID_5297770854488311778" style="display: block; margin-top: 0px; margin-right: auto; margin-bottom: 10px; margin-left: auto; text-align: center; cursor: pointer; width: 199px; height: 200px; " />
JBOD: Just a Buch Or Drives
Al igual que RAID 0, JBOD (Just a Buch Or Drives, o solo un montón de discos) no es un RAID en el puro sentido. JBOD nos crea una sola partición en varios discos (o una sola partición a partir de varias particiones), comportándose como si fuera una sola partición. Al contrario que RAID 0 los datos no se dividen entre los discos, sino que se comporta exactamente igual que si de un solo disco se tratara, siendo el tamaño de éste el resultado de la suma de los tamaños de los discos.
Una ventaja de JBOD sobre RAID 0 es que si falla un disco, sólo se pierde la información que contenga este, mientras que con RAID 0 el fallo en un disco supone la perdida total de datos. Al contrario que RAID 0, JBOD no aporta ninguna mejora en el rendimiento del sistema, siendo el rendimiento del conjunto igual al del componente más lento.
Tanto RAID 0 como JBOD se pueden hacer con un solo disco duro o con varios, siendo una solución muy interesante cuando tenemos varios discos de poca capacidad y queremos hacer con ellos un solo disco de gran capacidad o bien cuando el sistema operativo no soporta gestionar discos de gran capacidad. En cuanto a obtener una mejora significativa en el rendimiento con los discos duros actuales, tendríamos que montar un RAID por Hardware, a ser posible con una tarjeta para cada disco, por lo que el costo de esto se dispararía, a igual que las posibilidades de errores, que se multiplicarían por el número de elementos que integren el RAID.
Hay que aclarar que en un RAID 0 montado en un sólo disco duro NO tenemos ningún incremento en el rendimiento, ya que este siempre será el del disco sobre el que se monta.
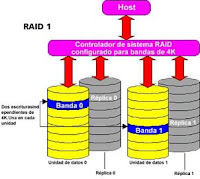
RAID 1: Mirroring «Redundancia. Más rápido que un disco y más seguro»
También llamado «Mirroring» o «Duplicación» (Creación de discos en espejo). Se basa en la utilización de discos adicionales sobre los que se realiza una copia en todo momento de los datos que se están modificando. RAID 1 ofrece una excelente disponibilidad de los datos mediante la redundancia total de los mismos. Para ello, se duplican todos los datos de una unidad o matriz en otra. De esta manera se asegura la integridad de los datos y la tolerancia al fallo, pues en caso de avería, la controladora sigue trabajando con los discos no dañados sin detener el sistema. Los datos se pueden leer desde la unidad o matriz duplicada sin que se produzcan interrupciones. RAID 1 es una alternativa costosa para los grandes sistemas, ya que las unidades se deben añadir en pares para aumentar la capacidad de almacenamiento. Sin embargo, RAID 1 es una buena solución para las aplicaciones que requieren redundancia cuando hay sólo dos unidades disponibles. Los servidores de archivos pequeños son un buen ejemplo. Se necesita un mínimo de dos unidades para implementar una solución RAID 1.
RAID 0+1/ RAID 0/1 ó RAID 10: «Ambos mundos»
Combinación de los arrays anteriores que proporciona velocidad y tolerancia al fallosimultáneamente. El nivel de RAID 0+1 fracciona los datos para mejorar el rendimiento, pero también utiliza un conjunto de discos duplicados para conseguir redundancia de datos. Al ser una variedad de RAID híbrida, RAID 0+1 combina las ventajas de rendimiento de RAID 0 con la redundancia que aporta RAID 1. Sin embargo, la principal desventaja es que requiere un mínimo de cuatro unidades y sólo dos de ellas se utilizan para el almacenamiento de datos. Las u
nidades se deben añadir en pares cuando se aumenta la capacidad, lo que multiplica por dos los costes de almacenamiento. El RAID 0+1 tiene un rendimiento similar al RAID 0 y puede tolerar el fallo de varias unidades de disco. Una configuración RAID 0+1 utiliza un número par de discos (4, 6, 8) creando dos bloques. Cada bloque es una copia exacta del otro, de ahí RAID 1, y dentro de cada bloque la escritura de datos se realiza en modo de bloques alternos, el sistema RAID 0. RAID 0+1 es una excelente solución para cualquier uso que requiera gran rendimiento y tolerancia a fallos, pero no una gran capacidad. Se utiliza normalmente en entornos como servidores de aplicaciones, que permiten a los usuarios acceder a una aplicación en el servidor y almacenar datos en sus discos duros locales, o como los servidores web, que permiten a los usuarios entrar en el sistema para localizar y consultar información. Este nivel de RAID es el más rápido, el más seguro, pero por contra el más costoso de implementar.
RAID 2: «Acceso paralelo con discos especializados. Redundancia a través del código Hamming»
El RAID nivel 2 adapta la técnica comúnmente usada para detectar y corregir errores en memorias de estado sólido. En un RAID de nivel 2, el código ECC (Error Correction Code) se intercala a través de varios discos a nivel de bit. El método empleado es el Hamming. Puesto que el código Hamming se usa tanto para detección como para corrección de errores (Error Detection and Correction), RAID 2 no hace uso completo de las amplias capacidades de detección de errores contenidas en los discos. Las propiedades del código Hamming también restringen las configuraciones posibles de matrices para RAID 2, particularmente el cálculo de paridad de los discos. Por lo tanto, RAID 2 no ha sido apenas implementado en productos comerciales, lo que también es debido a que requiere características especiales en los discos y no usa discos estándares.
Debido a que es esencialmente una tecnología de acceso paralelo, RAID 2 está más indicado para aplicaciones que requieran una alta tasa de transferencia y menos conveniente para aquellas otras que requieran una alta tasa de demanda I/O.
RAID 3: «Acceso síncrono con un disco dedicado a paridad»
Dedica un único disco al almacenamiento de información de paridad. La información de ECC (Error Checking and Correction) se usa para detectar errores. La recuperación de datos se consigue calculando el O exclusivo (XOR) de la información registrada en los otros discos. La operación I/O accede a todos los discos al mismo tiempo, por lo cual el RAID 3 es mejor para sistemas de un sólo usuario con aplicaciones que contengan grandes registros.
RAID 3 ofrece altas tasas de transferencia, alta fiabilidad y alta disponibilidad, a un coste intrínsicamente inferior que un Mirroring (RAID 1). Sin embargo, su rendimiento de transacción es pobre porque todos los discos del conjunto operan al unísono.
Se necesita un mínimo de tres unidades para implementar una solución RAID 3.

RAID 4: «Acceso Independiente con un disco dedicado a paridad.»
Basa su tolerancia al fallo en la utilización de un disco dedicado a guardar la información de paridad calculada a partir de los datos guardados en los otros discos. En caso de avería de cualquiera de las unidades de disco, la información se puede reconstruir en tiempo real mediante la realización de una operación lógica de O exclusivo. Debido a su organización interna, este RAID es especialmente indicado para el almacenamiento de ficheros de gran tamaño, lo cual lo hace ideal para aplicaciones gráficas donde se requiera, además, fiabilidad de los datos. Se necesita un mínimo de tres unidades para implementar una solución RAID 4. La ventaja con el RAID 3 está en que se puede acceder a los discos de forma individual.
RAID 5: «Acceso independiente con paridad distribuida.»
Este array ofrece tolerancia al fallo, pero además, optimiza la capacidad del sistemapermitiendo una utilización de hasta el 80% de la capacidad del conjunto de discos. Esto lo consigue mediante el cálculo de información de paridad y su almacenamiento alternativo por bloques en todos los discos del conjunto. La información del usuario se graba por bloques y de forma alternativa en todos ellos. De esta manera, si cualquiera de las unidades de disco falla, se puede recuperar la información en tiempo real, sobre la marcha, mediante una simple operación de lógica de O exclusivo, sin que el servidor deje de funcionar.
Así pues, para evitar el problema de cuello de botella que plantea el RAID 4 con el disco de comprobación, el RAID 5 no asigna un disco específico a esta misión sino que asigna un bloque alternativo de cada disco a esta misión de escritura. Al distribuir la función de comprobación entre todos los discos, se disminuye el cuello de botella y con una cantidad suficiente de discos puede llegar a eliminarse completamente, proporcionando una velocidad equivalente a un RAID 0.
RAID 5 es el nivel de RAID más eficaz y el de uso preferente para las aplicaciones de servidor básicas para la empresa. Comparado con otros niveles RAID con tolerancia a fallos, RAID 5 ofrece la mejor relación rendimiento-coste en un entorno con varias unidades. Gracias a la combinación del fraccionamiento de datos y la paridad como método para recuperar los datos en caso de fallo, constituye una solución ideal para los entornos de servidores en los que gran parte del E/S es aleatoria, la protección y disponibilidad de los datos es fundamental y el coste es un factor importante. Este nivel de array es especialmente indicado para trabajar con sistemas operativos multiusuarios.
Se necesita un mínimo de tres unidades para implementar una solución RAID 5.
Los niveles 4 y 5 de RAID pueden utilizarse si se disponen de tres o más unidades de disco en la configuración, aunque su resultado óptimo de capacidad se obtiene con siete o más unidades. RAID 5 es la solución más económica por megabyte, que ofrece la mejor relación de precio, rendimiento y disponibilidad para la mayoría de los servidores.

RAID 6: «Acceso independiente con doble paridad»
Similar al RAID 5, pero incluye un segundo esquema de paridad distribuido por los distintos discos y por tanto ofrece tolerancia extremadamente alta a los fallos y a las caídas de disco, ofreciendo dos niveles de redundancia. Hay pocos ejemplos comerciales en la actualidad, ya que su coste de implementación es mayor al de otros niveles RAID, ya que las controladoras requeridas que soporten esta doble paridad son más complejas y caras que las de otros niveles RAID. Así pues, comercialmente no se implementa.
Niveles RAID anidados
Muchas controladoras permiten anidar niveles RAID, es decir, que un RAID pueda usarse como elemento básico de otro en lugar de discos físicos. Resulta instructivo pensar en estos conjuntos como capas dispuestas unas sobre otras, con los discos físicos en la inferior.
Los RAIDs anidados se indican normalmente uniendo en un solo número los correspondientes a los niveles RAID usados, añadiendo a veces un «+» entre ellos. Por ejemplo, el RAID 10 (o RAID 1+0) consiste conceptualmente en múltiples conjuntos de nivel 1 almacenados en discos físicos con un nivel 0 encima, agrupando los anteriores niveles 1. En el caso del RAID 0+1 se usa más esta forma que RAID 01 para evitar la confusión con el RAID 1. Sin embargo, cuando el conjunto de más alto nivel es un RAID 0 (como en el RAID 10 y en el RAID 50), la mayoría de los vendedores eligen omitir el «+», a pesar de que RAID 5+0 sea más informativo.
Al anidar niveles RAID, se suele combinar un nivel RAID que proporcione redundancia con un RAID 0 que aumenta el rendimiento. Con estas configuraciones es preferible tener el RAID 0 como nivel más alto y los conjuntos redundantes debajo, porque así será necesario reconstruir menos discos cuando uno falle. (Así, el RAID 10 es preferible al RAID 0+1 aunque las ventajas administrativas de «dividir el espejo» del RAID 1 se perderían.)
Los niveles RAID anidados más comúnmente usados son:
- RAID 0+1: Un espejo de divisiones
- RAID 1+0: Una división de espejos
- RAID 30: Una división de niveles RAID con paridad dedicada
- RAID 100: Una división de una división de espejos
RAID 0+1 [editar]

Un RAID 0+1 (también llamado RAID 01, que no debe confundirse con RAID 1) es un RAID usado para replicar y compartir datos entre varios discos. La diferencia entre un RAID 0+1 y un RAID 1+0 es la localización de cada nivel RAID dentro del conjunto final: un RAID 0+1 es un espejo de divisiones.
Como puede verse en el diagrama, primero se crean dos conjuntos RAID 0 (dividiendo los datos en discos) y luego, sobre los anteriores, se crea un conjunto RAID 1 (realizando un espejo de los anteriores). La ventaja de un RAID 0+1 es que cuando un disco duro falla, los datos perdidos pueden ser copiados del otro conjunto de nivel 0 para reconstruir el conjunto global. Sin embargo, añadir un disco duro adicional en una división, es obligatorio añadir otro al de la otra división para equilibrar el tamaño del conjunto.
Además, el RAID 0+1 no es tan robusto como un RAID 1+0, no pudiendo tolerar dos fallos simultáneos de discos salvo que sean en la misma división. Es decir, cuando un disco falla, la otra división se convierte en un punto de fallo único. Además, cuando se sustituye el disco que falló, se necesita que todos los discos del conjunto participen en la reconstrucción de los datos.
Con la cada vez mayor capacidad de las unidades de discos (liderada por las unidades serial ATA), el riesgo de fallo de los discos es cada vez mayor. Además, las tecnologías de corrección de errores de bit no han sido capaces de mantener el ritmo de rápido incremento de las capacidades de los discos, provocando un mayor riesgo de hallar errores físicos irrecuperables.
Dados estos cada vez mayores riesgos del RAID 0+1 (y su vulnerabilidad ante los fallos dobles simultáneos), muchos entornos empresariales críticos están empezando a evaluar configuraciones RAID más tolerantes a fallos que añaden un mecanismo de paridad subyacente. Entre los más prometedores están los enfoques híbridos como el RAID 0+1+5 (espejo sobre paridad única) o RAID 0+1+6 (espejo sobre paridad dual). Son los más habituales por las empresas.
RAID 1+0 [editar]

Un RAID 1+0, a veces llamado RAID 10, es parecido a un RAID 0+1 con la excepción de que los niveles RAID que lo forman se invierte: el RAID 10 es una división de espejos.
En cada división RAID 1 pueden fallar todos los discos salvo uno sin que se pierdan datos. Sin embargo, si los discos que han fallado no se reemplazan, el restante pasa a ser un punto único de fallo para
todo el conjunto. Si ese disco falla entonces, se perderán todos los datos del conjunto completo. Como en el caso del RAID 0+1, si un disco que ha fallado no se reemplaza, entonces un solo error de medio irrecuperable que ocurra en el disco espejado resultaría en pérdida de datos.
Debido a estos mayores riesgos del RAID 1+0, muchos entornos empresariales críticos están empezando a evaluar configuraciones RAID más tolerantes a fallos que añaden un mecanismo de paridad subyacente. Entre los más prometedores están los enfoques híbridos como el RAID 0+1+5 (espejo sobre paridad única) o RAID 0+1+6 (espejo sobre paridad dual).
El RAID 10 es a menudo la mejor elección para bases de datos de altas prestaciones, debido a que la ausencia de cálculos de paridad proporciona mayor velocidad de escritura.
RAID 30 [editar]

El RAID 30 o división con conjunto de paridad dedicado es una combinación de un RAID 3 y un RAID 0. El RAID 30 proporciona tasas de transferencia elevadas combinadas con una alta fiabilidad a cambio de un coste de implementación muy alto. La mejor forma de construir un RAID 30 es combinar dos conjuntos RAID 3 con los datos divididos en ambos conjuntos. El RAID 30 trocea los datos en bloque más pequeños y los divide en cada conjunto RAID 3, que a su vez lo divide en trozos aún menores, calcula la paridad aplicando un XOR a cada uno y los escriben en todos los discos del conjunto salvo en uno, donde se almacena la información de paridad. El tamaño de cada bloque se decide en el momento de construir el RAID.Etc…
El RAID 30 permite que falle un disco de cada conjunto RAID 3. Hasta que estos discos que fallaron sean reemplazados, los otros discos de cada conjunto que sufrió el fallo son puntos únicos de fallo para el conjunto RAID 30 completo. En otras palabras, si alguno de ellos falla se perderán todos los datos del conjunto. El tiempo de recuperación necesario (detectar y responder al fallo del disco y reconstruir el conjunto sobre el disco nuevo) representa un periodo de vulnerabilidad para el RAID.
RAID 100 [editar]
Un RAID 100, a veces llamado también RAID 10+0, es una división de conjuntos RAID 10. El RAID 100 es un ejemplo de «RAID cuadriculado», un RAID en el que conjuntos divididos son a su vez divididos conjuntamente de nuevo.
Todos los discos menos unos podrían fallar en cada RAID 1 sin perder datos. Sin embargo, el disco restante de un RAID 1 se convierte así en un punto único de fallo para el conjunto degradado. A menudo el nivel superior de división se hace por software. Algunos vendedores llaman a este nivel más alto un MetaLun o Soft Stripe..
Los principales beneficios de un RAID 100 (y de los RAIDs cuadriculados en general) sobre un único nivel RAID son mejor rendimiento para lecturas aleatorias y la mitigación de los puntos calientes de riesgo en el conjunto. Por estas razones, el RAID 100 es a menudo la mejor elección para bases de datos muy grandes, donde el conjunto software subyacente limita la cantidad de discos físicos permitidos en cada conjunto estándar. Implementar niveles RAID anidados permite eliminar virtualmente el límite de unidades físicas en un único volumen lógico.
RAID 50 [editar]
Un RAID 50, a veces llamado también RAID 5+0, combina la división a nivel de bloques de un RAID 0 con la paridad distribuida de un RAID 5, siendo pues un conjunto RAID 0 dividido de elementos RAID 5.
Un disco de cada conjunto RAID 5 puede fallar sin que se pierdan datos. Sin embargo, si el disco que falla no se reemplaza, los discos restantes de dicho conjunto se convierten en un punto único de fallo para todo el conjunto. Si uno falla, todos los datos del conjunto global se pierden. El tiempo necesario para recuperar (detectar y responder al fallo de disco y reconstruir el conjunto sobre el nuevo disco) representa un periodo de vulnerabilidad del conjunto RAID.
La configuración de los conjuntos RAID repercute sobre la tolerancia a fallos general. Una configuración de tres conjuntos RAID 5 de siete discos cada uno tiene la mayor capacidad y eficiencia de almacenamiento, pero sólo puede tolerar un máximo de tres fallos potenciales de disco. Debido a que la fiabilidad del sistema depende del rápido reemplazo de los discos averiados para que e
l conjunto pueda reconstruirse, es común construir conjuntos RAID 5 de seis discos con un disco de reserva en línea (hot spare) que permite empezar de inmediato la reconstrucción en caso de fallo del conjunto. Esto no soluciona el problema de que el conjunto sufre un estrés máximo durante la reconstrucción dado que es necesario leer cada bit, justo cuando es más vulnerable. Una configuración de siete conjuntos RAID 5 de tres discos cada uno puede tolerar hasta siete fallos de disco pero tiene menor capacidad y eficiencia de almacenamiento.
El RAID 50 mejora el rendimiento del RAID 5, especialmente en escritura, y proporciona mejor tolerancia a fallos que un nivel RAID único. Este nivel se recomienda para aplicaciones que necesitan gran tolerancia a fallos, capacidad y rendimiento de búsqueda aleatoria.
A medida que el número de unidades del conjunto RAID 50 crece y la capacidad de los discos aumenta, el tiempo de recuperación lo hace también.
Niveles RAID propietarios
Aunque todas las implementaciones de RAID difieren en algún grado de la especificación idealizada, algunas compañías han desarrollado implementaciones RAID completamente propietarias que difieren sustancialmente de todas las demás.
Paridad doble

Una adición frecuente a los niveles RAID existentes es la paridad doble, a veces implementada y conocida como paridad diagonal.2 Como en el RAID 6, hay dos conjuntos de información de chequeo deparidad, pero a diferencia de aquél, el segundo conjunto no es otro conjunto de puntos calculado sobre un síndrome polinomial diferente para los mismos grupos de bloques de datos, sino que se calcula la paridad extra a partir de un grupo diferente de bloques de datos. Por ejemplo, sobre el gráfico tanto el RAID 5 como el RAID 6 calcularían la paridad sobre todos los bloques de la letra A para generar uno o dos bloques de paridad. Sin embargo, es bastante fácil calcular la paridad contra múltiples grupos de bloques, en lugar de sólo sobre los bloques de la letra A: puede calcularse la paridad sobre los bloques de la letra A y un grupo permutado de bloques.
De nuevo sobre el ejemplo, los bloques Q son los de la paridad doble. El bloque Q2 se calcularía como A2 xor B3 ‘xor P3, mientras el bloque Q3 se calcularía como A3 xor P2 xor C1 y el Q1 sería A1 xor B2xor C3. Debido a que los bloques de paridad doble se distribuyen correctamente, es posible reconstruir dos discos de datos que fallen mediante recuperación iterativa. Por ejemplo, B2 podría recuperarse sin usar ninguno de los bloque x1 ni x2 mediante el cálculo de B3 xor P3 xor Q2 = A2, luego A2 xor A3 xor P1 = A1, y finalmente A1 xor C3 xor Q1 = B2.
No es recomendable que el sistema de paridad doble funcione en modo degradado debido a su bajo rendimiento.
RAID 1.5
RAID 1.5 es un nivel RAID propietario de HighPoint a veces incorrectamente denominado RAID 15. Por la poca información disponible, parece ser una implementación correcta de un RAID 1. Cuando se lee, los datos se recuperan de ambos discos simultáneamente y la mayoría del trabajo se hace en hardware en lugar de en el controlador software.
RAID 7
RAID 7 es una marca registrada de Storage Computer Corporation, que añade cachés a un RAID 3 o RAID 4 para mejorar el rendimiento.
RAID S o RAID de paridad
RAID S es un sistema RAID de paridad distribuida propietario de EMC Corporation usado en sus sistemas de almacenamiento Symmetrix. Cada volumen reside en un único disco físico, y se combinan arbitrariamente varios volúmenes para el cálculo de paridad. EMC llamaba originalmente a esta característica RAID S y luego la rebautizó RAID de paridad (Parity RAID) para su plataforma Symmetrix DMX. EMC ofrece también actualmente un RAID 5 estándar para el Symmetrix DMX.
Matrix RAID

Matrix RAID (‘matriz RAID’) es una característica que apareció por vez primera en la BIOS RAID Intel ICH6R. No es un nuevo nivel RAID.
El Matrix RAID utiliza dos o más discos físicos, asignando partes de idéntico tamaño de cada uno de ellos diferentes niveles de RAID. Así, por ejemplo, sobre 4 discos de un total de 600GB, se pueden usar 200 en raid 0, 200 en raid 10 y 200 en raid 5. Actualmente, la mayoría de los otros productos RAID BIOS de gama baja sólo permiten que un disco participen en un único conjunto.
Este producto está dirigido a los usuarios domésticos, proporcionando una zona segura (la sección RAID 1) para documentos y otros ficheros que se desean almacenar redundantemente y una zona más rápida (la sección RAID 0) para el sistema operativo, aplicaciones, etcétera.
Linux MD RAID 10
La controladora RAID software del kernel de Linux (llamada md, de multiple disk, ‘disco múltiple’) puede ser usada para construir un conjunto RAID 1+0 clásico, pero también permite un único nivel RAID 10 con algunas extensiones interesantes.
En particular, soporta un espejado de k bloques en n unidades cuando k no es divisible por n. Esto se hace repitiendo cada bloque k veces al escribirlo en un conjunto RAID 0 subyacente de n unidades. Evidentemente esto equivale a la configuración RAID 10 estándar.
Linux también permite crear otras configuraciones RAID usando la controladora md (niveles 0, 1, 4, 5 y 6) además de otros usos no RAID como almacenamiento multirruta y LVM2.
IBM ServeRAID 1E [editar]

{kind=link}
La serie de adaptadores IBM ServeRAID soportan un espejado doble de un número arbitrario de discos, como se ilustra en el gráfico.
Esta configuración es tolerante a fallos de unidades no adyacentes. Otros sistemas de almacenamiento como el StorEdge T3 de Sun soportan también este modo.
RAID Z [editar]
El sistema de ficheros ZFS de Sun Microsystems implementa un esquema de redundancia integrado parecido al RAID 5 que se denomina RAID Z. Esta configuración evita el «agujero de escritura» del RAID 5[1] y la necesidad de la secuencia leer-modificar-escribir para operaciones de escrituras pequeñas efectuando sólo escrituras de divisiones (stripes) completas, espejando los bloques pequeños en lugar de protegerlos con el cálculo de paridad, lo que resulta posible gracias a que el sistema de ficheros conoce la estructura de almacenamiento subyacente y puede gestionar el espacio adicional cuando lo necesita.
Posibilidades de RAID
Lo que RAID puede hacer
- RAID puede mejorar el uptime. Los niveles RAID 1, 0+1 o 10, 5 y 6 (sus variantes, como el 50) permiten que un disco falle mecánicamente y que aun así los datos del conjunto sigan siendo acce
sibles para los usuarios. En lugar de exigir que se realice una restauración costosa en tiempo desde una cinta, DVD o algún otro medio de respaldo lento, un RAID permite que los datos se recuperen en un disco de reemplazo a partir de los restantes discos del conjunto, mientras al mismo tiempo permanece disponible para los usuarios en un modo degradado. Esto es muy valorado por las empresas, ya que el tiempo de no disponibilidad suele tener graves repercusiones. Para usuarios domésticos, puede permitir el ahorro del tiempo de restauración de volúmenes grandes, que requerirían varios DVD o cintas para las copias de seguridad. - RAID puede mejorar el rendimiento de ciertas aplicaciones. Los niveles RAID 0, 5 y 6 usan variantes de división (striping) de datos, lo que permite que varios discos atiendan simultáneamente las operaciones de lectura lineales, aumentando la tasa de transferencia sostenida. Las aplicaciones de escritorio que trabajan con ficheros grandes, como la edición de vídeo e imágenes, se benefician de esta mejora. También es útil para las operaciones de copia de respaldo de disco a disco. Además, si se usa un RAID 1 o un RAID basado en división con un tamaño de bloque lo suficientemente grande se logran mejoras de rendimiento para patrones de acceso que implique múltiples lecturas simultáneas (por ejemplo, bases de datos multiusuario).
Lo que RAID no puede hacer
- RAID no protege los datos. Un conjunto RAID tiene un sistema de ficheros, lo que supone un punto único de fallo al ser vulnerable a una amplia variedad de riesgos aparte del fallo físico de disco, por lo que RAID no evita la pérdida de datos por estas causas. RAID no impedirá que un virus destruya los datos, que éstos se corrompan, que sufran la modificación o borrado accidental por parte del usuario ni que un fallo físico en otro componente del sistema afecten a los datos. RAID tampoco supone protección alguna frente a desastres naturales o provocados por el hombre como incendios o inundaciones. Para proteger los datos, deben realizarse copias de seguridad en medios tales como DVD, cintas o discos duros externos, y almacenarlas en lugares geográficos distantes.
- RAID no simplifica la recuperación de un desastre. Cuando se trabaja con un solo disco, éste es accesible normalmente mediante un controlador ATA o SCSI incluido en la mayoría de los sistemas operativos. Sin embargo, las controladoras RAID necesitan controladores software específicos. Las herramientas de recuperación que trabajan con discos simples en controladoras genéricas necesitarán controladores especiales para acceder a los datos de los conjuntos RAID. Si estas herramientas no los soportan, los datos serán inaccesibles para ellas.
- RAID no mejora el rendimiento de las aplicaciones. Esto resulta especialmente cierto en las configuraciones típicas de escritorio. La mayoría de aplicaciones de escritorio y videojuegos hacen énfasis en la estrategia de buffering y lostiempos de búsqueda de los discos. Una mayor tasa de transferencia sostenida supone poco beneficio para los usuarios de estas aplicaciones, al ser la mayoría de los ficheros a los que se accede muy pequeños. La división de discos de un RAID 0 mejora el rendimiento de transferencia lineal pero no lo demás, lo que hace que la mayoría de las aplicaciones de escritorio y juegos no muestren mejora alguna, salvo excepciones. Para estos usos, lo mejor es comprar un disco más grande, rápido y caro en lugar de dos discos más lentos y pequeños en una configuración RAID 0.
- RAID no facilita el traslado a un sistema nuevo. Cuando se usa un solo disco, es relativamente fácil trasladar el disco a un sistema nuevo: basta con conectarlo, si cuenta con la misma interfaz. Con un RAID no es tan sencillo: la BIOS RAID debe ser capaz de leer los metadatos de los miembros del conjunto para reconocerlo adecuadamente y hacerlo disponible al sistema operativo. Dado que los distintos fabricantes de controladoras RAID usan diferentes formatos de metadatos (incluso controladoras de un mismo fabricante son incompatibles si corresponden a series diferentes) es virtualmente imposible mover un conjunto RAID a una controladora diferente, por lo que suele ser necesario mover también la controladora. Esto resulta imposible en aquellos sistemas donde está integrada en la placa base. Esta limitación puede obviarse con el uso de RAIDs por software, que a su vez añaden otras diferentes (especialmente relacionadas con el rendimiento).